
관찰 가능성(Observability) vs 모니터링(Monitoring)
차이점은 무엇일까요?
엔터프라이즈 IT 및 소프트웨어 기반 소비자 제품 개발은 점점 더 복잡해지고 있습니다. 인터넷은 지리적으로 멀리 떨어진 위치에 있는 거대한 데이터 센터에서 IT 인프라 서비스를 제공합니다. 기업은 이러한 서비스를 인프라 및 플랫폼 서비스 계층에 걸쳐 마이크로 서비스 및 컨테이너와 같은 분산 기능으로 사용하곤 합니다. 고객은 인터넷을 통한 새로운 버전의 릴리스를 통해 빠른 기능 향상을 기대합니다.
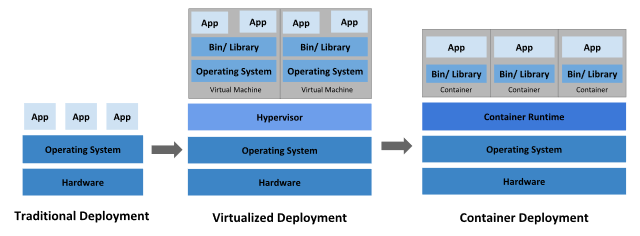
그림1. 컨테이너 구조
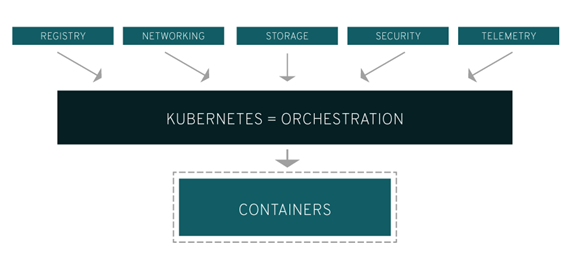
그림2. '쿠퍼네틱스'란?
|
1) 가상머신(VM) • 크기는 기가바이트 단위. • VM은 자체 OS를 포함하고 있어 리소스 집약적인 기능 여러 개를 동시에 수행할 수 있음. • VM에서 사용할 수 있는 리소스가 늘어남에 따라 전체 서버, OS, 데스크톱, 데이터베이스, 네트워크를 추상화, 분할, 복제, 에뮬레이션할 수 있음.
2) 컨테이너(Container) • 크기가 메가바이트 단위로 민첩성을 확보하는 핵심 가상화 기술. • 앱보다 크거나 실행하는데 필수적인 모든 파일이 컨테이너에 패키징되는 것은 아니며, 특정 작업을 수행하는 단일 기능(마이크로서비스라고 함)이 컨테이너에 패키징됨. • 컨테이너는 경량화 속성과 공유 운영 체제(OS)로 인해 여러 환경 간에 매우 쉽게 이동 가능.
3) 마이크로 서비스(Micro-service) • 거대한 어플리케이션을 최소한의 기능별로 나누어 서비스. • 컨테이너를 사용하면 하나의 큰 어플에서 dependency를 최소한 서비스 단위로 나누어 빠른 배포 가능. • 최소한으로 나누어 쓰니 변경이 발생하더라도 분리된 다른 기능들에 영향 미치지 않음.
4) 쿠버네티스(Kubernetes, K8S) • 컨테이너 오케스트레이션 툴. • 오케스트레이션 이란? 컨테이너를 스케줄링/스케일링/클러스터링/운영자동화/로깅 및 모니터링 하는 것. • 쿠버네티스를 사용하여 수행할 수 있는 작업: - 여러 호스트에 걸쳐 컨테이너를 오케스트레이션 수행 - 하드웨어를 최대한 활용하여 애플리케이션을 실행하는 데 필요한 리소스를 극대화. - 애플리케이션 배포 및 업데이트를 제어하고 자동화. - 스토리지를 장착 및 추가해 스테이트풀(stateful) 애플리케이션을 실행. - 컨테이너화된 애플리케이션과 해당 리소스를 즉시 확장. - 선언적으로(Declaratively) 서비스를 관리함으로써, 배포한 애플리케이션이 항상 배포 목적대로 실행. - 자동 배치, 자동 재시작, 자동 복제, 자동 확장을 사용해 애플리케이션 상태 확인과 셀프 복구를 수행. |
이러한 최종 사용자 요구 사항을 충족하기 위해 IT 서비스 제공 업체와 비즈니스 조직은 성능을 간소화하고 IT 시스템의 고유한 복잡성을 완화하여 백엔드 IT 인프라 운영의 안정성과 예측 가능성을 개선해야 합니다. 이를 위해 우리는 시스템 신뢰성을 최적화하기 위해 인프라 성능과 관련된 메트릭(metric) 및 데이터 세트를 면밀히 관찰하고 모니터링합니다.
시스템 관찰 가능성과 모니터링은 모두 시스템 신뢰성을 달성하는데 중요한 역할을 하지만 같은 것은 아닙니다. 관찰 가능성과 모니터링의 차이점을 이해하고 클라우드 기반 엔터프라이즈 IT 운영에서 가시성과 제어가 얼마나 중요한지 알아 보겠습니다.
-LIST-
(목차를 클릭하시면 해당 내용으로 바로 이동합니다.)
1. 관찰가능성 (Observability)란?
관찰 가능성은 시스템의 외부 출력에 대한 결과 값(지식)으로부터 시스템의 내부 상태를 얼마나 잘 추론 할 수 있는지를 나타내는 척도입니다. 출력 값 측정으로부터 시스템의 상태를 추정하도록 설계된 동적 시스템을 상태 관찰 가능성 또는 단순히 해당 시스템의 관찰 가능성이라 합니다. – 위키피디아
관찰 가능성은 시스템의 외부 출력을 기반으로 시스템의 내부 상태를 추론하는 기능입니다. 제어 이론에서 관찰 가능성은 외부 입력을 조작하여 시스템의 내부 상태를 제어하는 기능인 제어 가능성에 대한 수학적 이중(mathematical dual, A의 이중이 B이면 B의 이중은 A임) 입니다.
그러나 실제로 제어 가능성은 수학적으로 평가하기가 어렵습니다. 따라서 시스템 관찰 가능성은 시스템의 내부 상태에 대한 의미있는 결론에 도달하기 위해 출력을 평가하는 방법입니다.
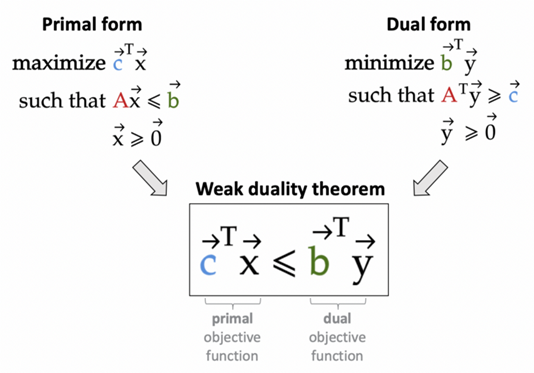
그림3. 수학적 이중(mathematical dual)
엔터프라이즈 IT에서 분산 인프라 구성 요소는 소프트웨어 및 가상화의 여러 추상화 계층을 통해 작동합니다. 이 환경에서는 시스템 제어 가능성을 분석하고 계산하는 것이 비실용적이고 어렵습니다.
대신, 일반적인 관행은 개별 하드웨어 구성 요소 및 시스템의 성능을 이해하기 위해 인프라 성능 로그 및 메트릭을 관찰하고 모니터링하는 것입니다. 고급 로그 분석 및 AI(AIOps)는 하드웨어 성능과 관련된 인시던트 및 이벤트를 평가하여 시스템 신뢰성에 대한 잠재적인 영향을 예측합니다. 그런 다음 IT 팀은 최종 사용자에게 미치는 영향을 줄이기 위해 선제적(Proactive)으로 수정 조치를 채택 할 수 있습니다 .
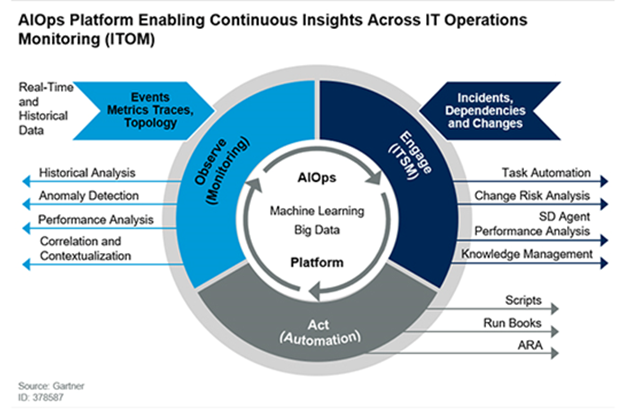
그림4. AIOps 플랫폼에 대한 Gartner의 시각화
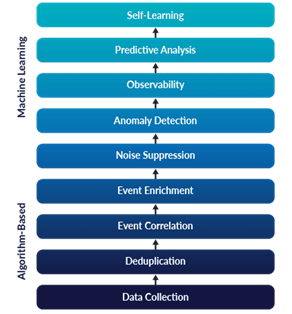
그림5. AIOps 의 주요 기능 (출처: blog.silver-storm.com/the-truth-aiops)
|
AIOps 플랫폼의 주요 기능 1) 업무를 자동화 → 일상 업무에는 사용자 요청과 중요하지 않은 IT 시스템 경고가 포함된다. 예를 들어, AIOps는 헬프 데스크 시스템이 자원을 자동으로 프로비저닝하기 위한 사용자 요청을 처리하고 이행할 수 있도록 할 수 있다. 또한 AIOps 플랫폼은 경고를 평가하고 사용 가능한 관련 지표와 지원 데이터가 정상 매개변수 내에 있으므로 조치가 필요하지 않다고 판단할 수 있습니다. 2) 인간보다 더 빠르고 정확하게 문제점을 인식 → IT 전문가는 중요하지 않은 시스템에서 알려진 멀웨어 이벤트를 처리할 수 있지만 중요한 서버에서 시작되는 비정상적인 다운로드 또는 프로세스는 무시합니다. 이 위협을 감시하지 않기 때문이다. AIOps는 이 시나리오를 다르게 다루고, 동작이 표준 범위를 벗어났기 때문에 중요 시스템에서 발생할 수 있는 공격이나 감염으로 우선순위를 정하고, 안티멀웨어 기능을 실행하여 알려진 멀웨어 이벤트를 분석합니다. 3) 원할한 데이터 습득을 위한 데이터 관련 팀 간의 상호 작용 필요 → 전 세계적으로 수천 대의 장치와 수백만 개의 노드를 관리하는 대규모 조직의 경우 메트릭, 이벤트, 스트리밍 데이터, 트레이스 및 로그 데이터를 포함하여 환경에서 사용 가능한 모든 복잡한 머신 데이터를 수동으로 선별하고 예측할 수있을 가능성은 거의 없습니다. 주어진 시간 내에 응용 프로그램 또는 시스템 오류를 유연하고 포괄적인 데이터 수집 메커니즘이 AIOps 도구에 필요한 것입니다. |
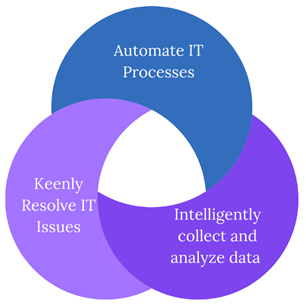
그림6. AIOps의 목표 (출처: www.TheChief.io)
2. 모니터링(Monitoring) 이란?
어떤 대상을 감시, 관찰한다는 뜻으로 모니터링의 목적은 지속적인 감시, 감찰을 통해 대상의 상태나 가용성, 변화 등을 확인하고 대비하는 것입니다. 즉 "어떤 대상의 상태나 상황을 지속적으로 감시, 관찰하여 예기치 못한 상황과 오류를 대비하고 극복한다"라고 할 수 있습니다. 특히 IT 서비스 분야에서는 기본적으로 미리 계획되어 한정된 비용과 리소스를 가지고 서비스를 제공하기 때문에 사용자 경험을 중요시하는 IT 서비스에서는 그 서비스가 어떤 환경에서 운영되든 모니터링의 중요성은 결코 낮게 평가 될 수가 없습니다.
확장성과 유연성을가진 클라우드 플랫폼에서는 지속적인 모니터링을 통해 수집된 데이터를 기반으로 시스템 규모의 확장과 축소를 빠르게 결정해야 하기 때문에 더욱더 중요합니다.
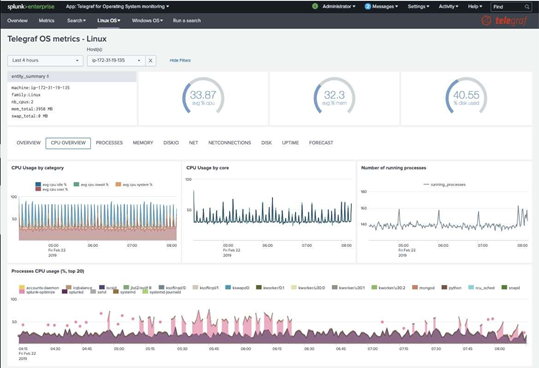
그림7. Telegraf for Operation System Monitoring - Linux
3. 모니터링 및 관찰 가능성 비교
로그 분석 및 모니터링과, ITSM(IT Service Management) 도구를 사용하여 모니터링 되는 크고 복잡한 데이터 센터의 인프라 시스템의 예를 사용하겠습니다. 너무 많은 데이터 포인트를 지속적으로 분석하면 불필요한 경고, 데이터 및 잘못된 플래그 정보가 많이 생성됩니다. 정확하게 메트릭이 평가되고 불필요한 노이즈가 AI 기반 인프라 모니터링 솔루션을 사용하여 정확하게 필터링되지 않는 한 인프라는 낮은 관측 가능성 특성을 나타낼 수 있습니다.
반면에 단일 서버 시스템은 하드웨어 에너지 소비, 온도, 데이터 전송 속도 및 처리 속도와 같은 메트릭 및 매개 변수를 사용하여 쉽게 모니터링 할 수 있습니다. 이러한 매개 변수는 내부 시스템 구성 요소의 상태와 밀접한 관련이 있습니다. 따라서 시스템은 높은 관찰 가능성을 보여줍니다. 에너지 및 온도 측정 기기 또는 소프트웨어 기반 모니터링 도구와 같은 기본 모니터링 도구를 사용하여 성능, 기대 수명 및 잠재적 성능 사고의 위험을 사전에 평가할 수 있습니다.
시스템의 관찰 가능성은 시스템의 단순성, 성능 메트릭의 통찰력 있는 표현 및 정확한 메트릭을 식별하는 모니터링 도구의 기능에 따라 달라집니다. 이 조합은 시스템의 고유한 복잡성에도 불구하고 내부 상태를 정확하게 표현하는데 필요한 통찰력을 제공합니다.
|
그림8. Gartner의 Monitoring Vs Observability

그림9. Monitoring Vs Observability 의 운명적 차이점 (출처: lightstep.com/observability/)
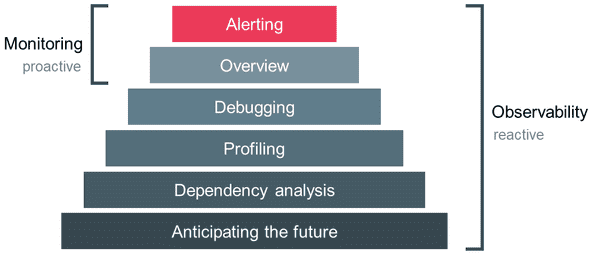
그림10. Monitoring Vs Observability 의 기능적 차이점 (출처: ish-ar.io/observability/)
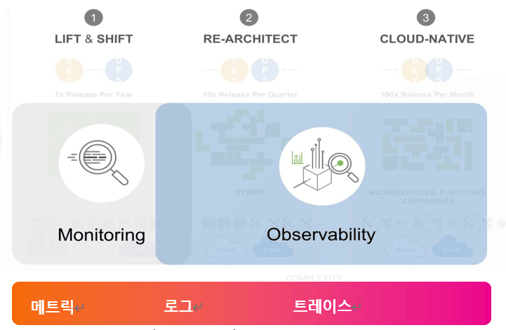
그림11. Splunk의 Monitoring Vs Observability
4. DevOps의 관찰 가능성
관찰 가능성의 개념은 DevOps의 소프트웨어 개발 수명주기(SDLC) 방법론에서 두드러집니다. 이전의 폭포수(waterfall) 및 애자일(agile) 프레임워크에서 개발자는 새로운 기능과 제품 라인을 구축하고 별도의 테스트 및 운영 팀이 소프트웨어 신뢰성을 테스트했습니다. 이렇게 격리된 접근 방식은 인프라 운영 및 모니터링 활동이 개발 범위에 포함되지 않음을 의미합니다.
개발자는 인프라 종속성과 애플리케이션 의미를 적절하게 이해하지 못했습니다. 따라서 앱과 서비스는 내재된 신뢰성이 낮습니다. 그래서 모니터링은 분산 인프라 시스템의 알려지지 않은 항목은 물론 알려진 항목에 대한 충분한 정보를 산출하지 못하는 한계를 가지고 있습니다.
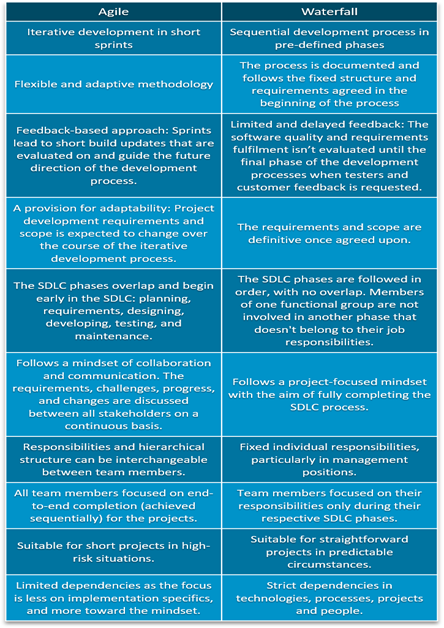
그림12. Agile vs Waterfall SDLC methodologies (출처: www.bmc.com/blogs/sdlc-software-development-lifecycle/)
DevOps의 보급은 SDLC에 많은 변화를 제공했습니다. 모니터링 목표는 더 이상 로그 데이터, 메트릭 및 분산 이벤트 트레이스를 수집하고 처리하는데 국한되지 않습니다. 모니터링은 이제 시스템을 더 잘 관찰 할 수 있도록 하는데 사용됩니다. 따라서 관찰 가능성의 범위는 개발 세그먼트를 포함하며 SDLC 파이프라인에서 작동하는 사람, 프로세스 및 기술에 의해 촉진됩니다.
개발자와 운영 팀 간의 커뮤니케이션 및 피드백은 QA가 테스트 단계에서 정확하고 통찰력 있는 모니터링을 산출하는데 도움이 되는 시스템의 관찰 가능성의 목표를 달성하는데 필요합니다. 결론적으로 DevOps 팀은 실제 성능 측정을 위해 시스템과 솔루션을 테스트하거나 사용 할 수 있습니다. 성능 피드백을 기반으로 지속적인 반복을 통해서 영향도(impact)가 최종 사용자에게 도달하기 전에 시스템의 잠재적인 문제를 식별하는 능력을 더욱 개선시킬 수 있습니다.
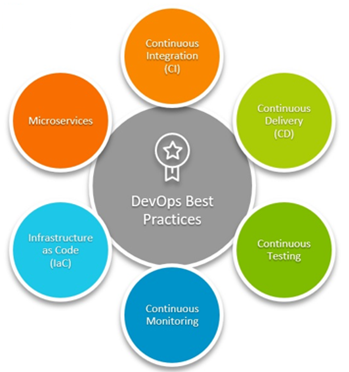
그림13. DevOps Best Practices (출처: www.bmc.com/blogs/devops-basics-introduction)
여러면에서 관찰 가능성은 DevOps와 유사한 강력한 인적 요소를 가지고 있습니다. 기술에만 국한되지 않고 적절한 관찰 가능성 목표에 도달하기 위한 접근 방식, 조직 문화 및 우선 순위에 의해서 우위를 점할 수 있습니다.
내용 관련하여 궁금하신 사항은 andy.park@sckcorp.co.kr 로 문의주시기 바랍니다.
